
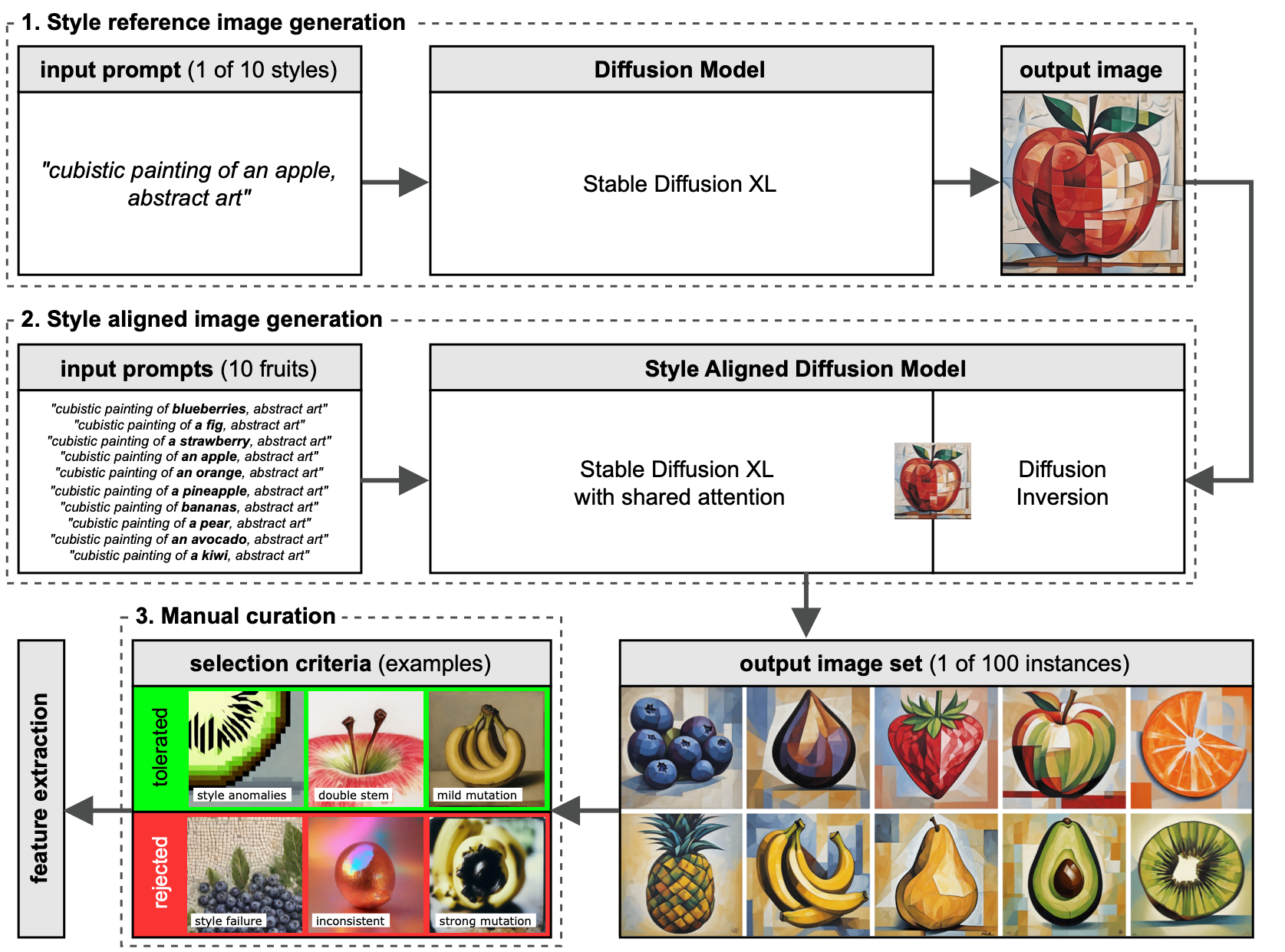
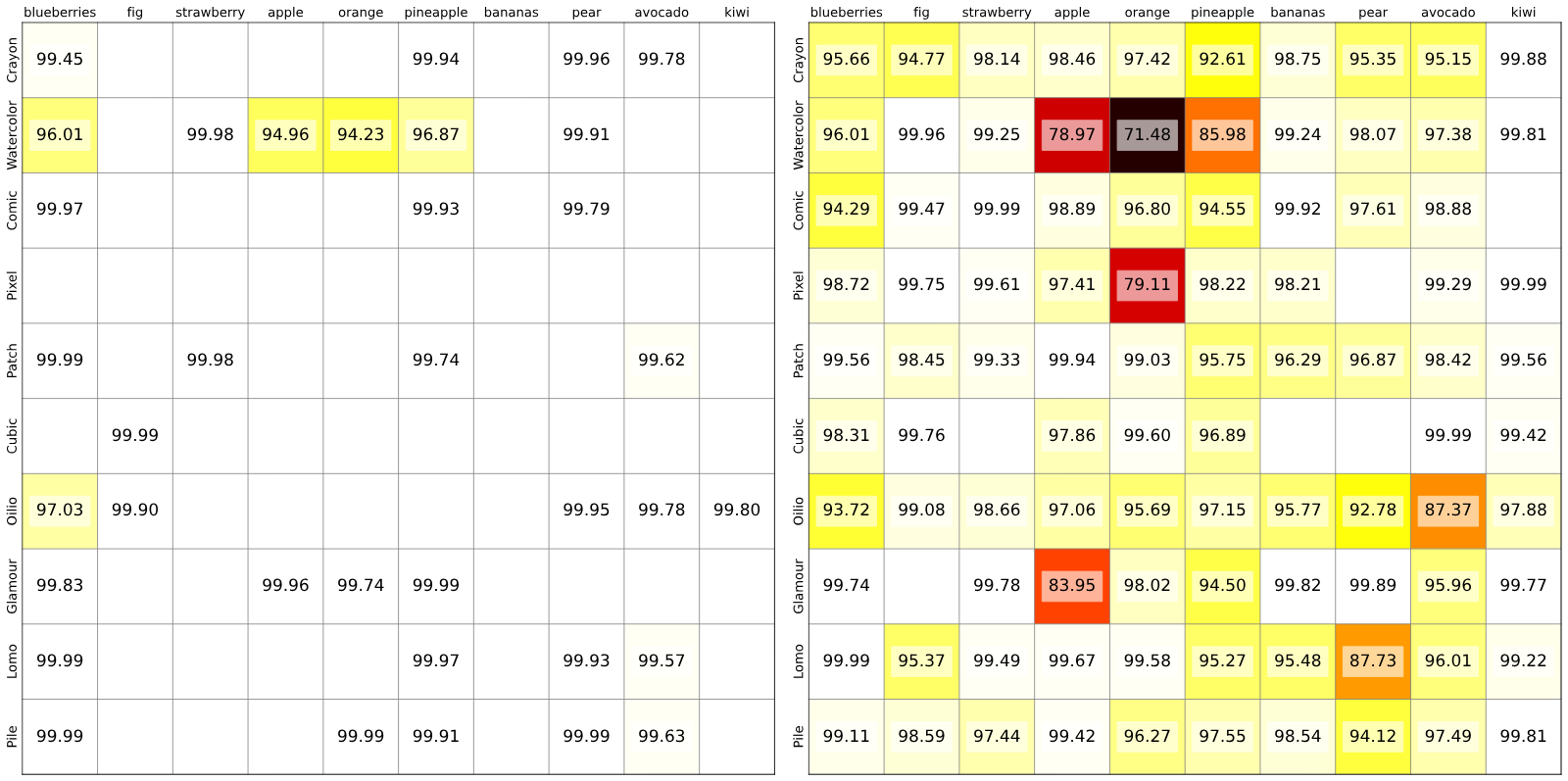
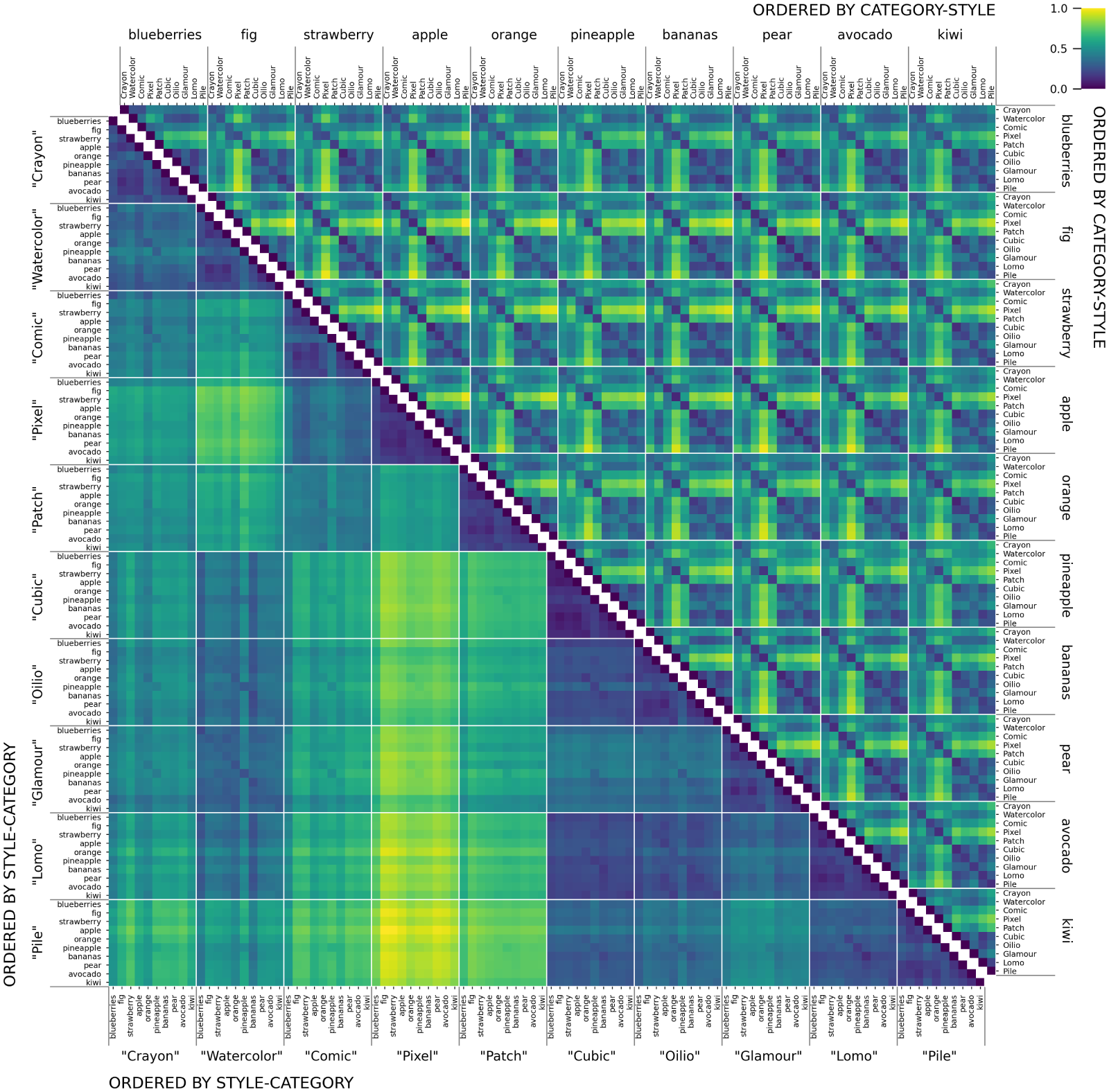
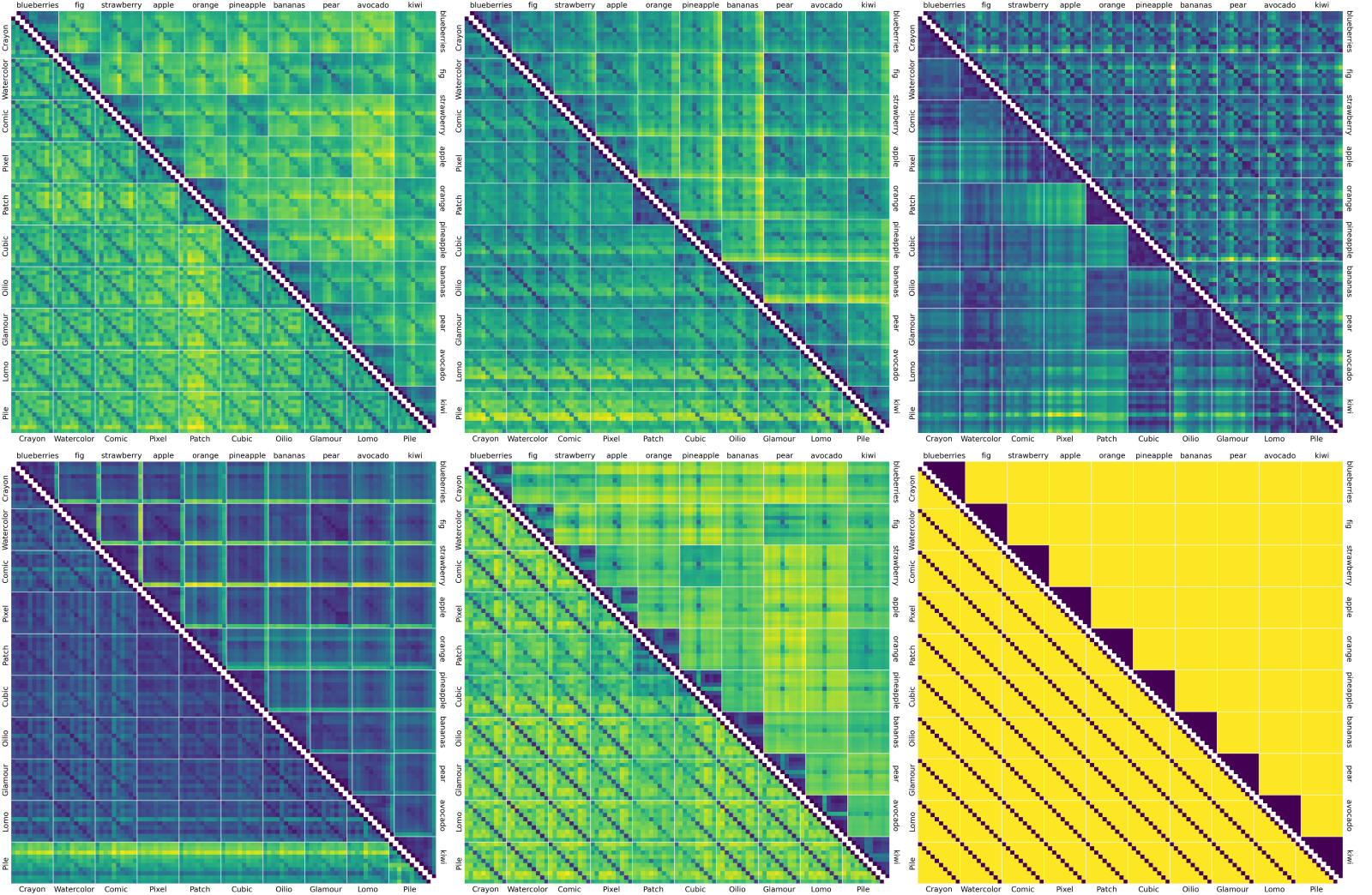
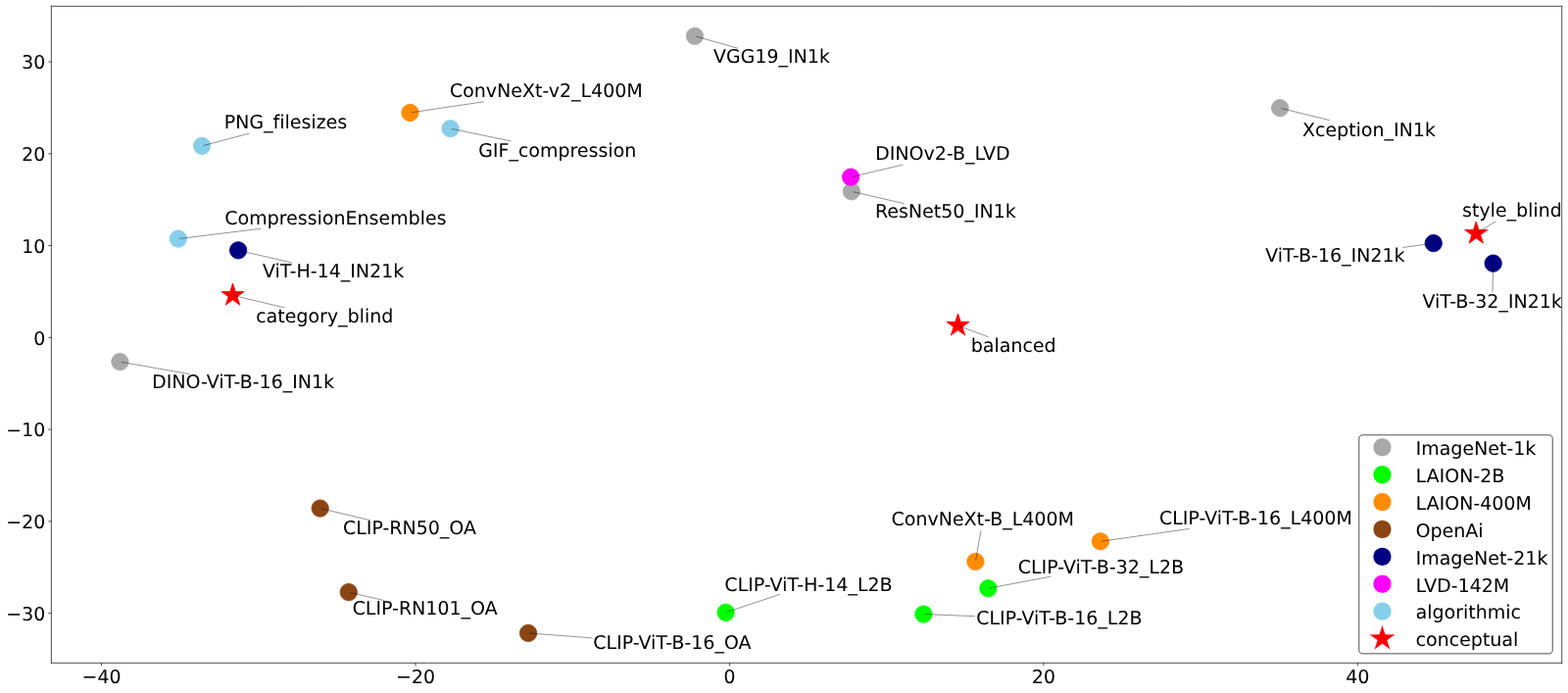
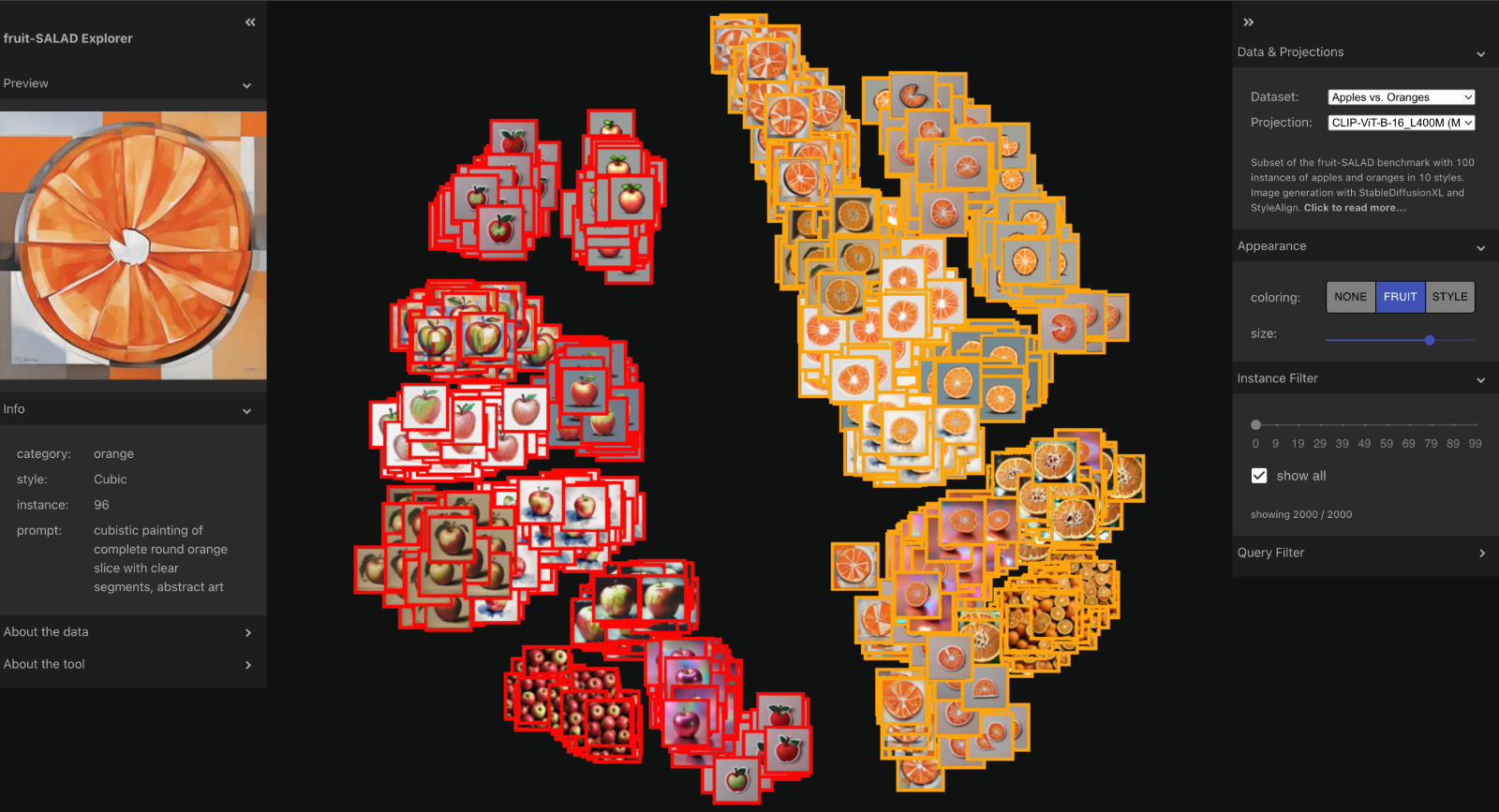
The notion of visual similarity is essential for computer vision, and in applications and studies revolving around vector embeddings of images. However, the scarcity of benchmark datasets poses a significant hurdle in exploring how these models perceive similarity. Here we introduce Style Aligned Artwork Datasets (SALADs), and an example of fruit-SALAD with 10,000 images of fruit depictions. This combined semantic category and style benchmark comprises 100 instances each of 10 easy-to-recognize fruit categories, across 10 easy distinguishable styles. Leveraging a systematic pipeline of generative image synthesis, this visually diverse yet balanced benchmark demonstrates salient differences in semantic category and style similarity weights across various computational models, including machine learning models, feature extraction algorithms, and complexity measures, as well as conceptual models for reference. This meticulously designed dataset offers a controlled and balanced platform for the comparative analysis of similarity perception. The SALAD framework allows the comparison of how these models perform semantic category and style recognition task to go beyond the level of anecdotal knowledge, making it robustly quantifiable and qualitatively interpretable.
@article{ohm2025FruitSALAD,
title = {fruit-SALAD: A Style Aligned Artwork Dataset to reveal similarity perception in image embeddings},
volume = {12},
issn = {2052-4463},
url = {https://doi.org/10.1038/s41597-025-04529-4},
doi = {10.1038/s41597-025-04529-4},
number = {1},
journal = {Scientific Data},
author = {Ohm, Tillmann and Karjus, Andres and Tamm, Mikhail V. and Schich, Maximilian},
year = {2025},
pages = {254},
}
@dataset{ohm_2024_11158522,
author = {Ohm, Tillmann},
title = {fruit-SALAD},
month = may,
year = 2024,
publisher = {Zenodo},
doi = {10.5281/zenodo.11158522},
url = {https://doi.org/10.5281/zenodo.11158522},
}
The fruit-SALAD Explorer is based on our Collection Space Navigator.